






电磁仿真(HFSS、CST、FEKO)时域频域台式集群配置推荐2018
目录
1.电磁仿真计算特点与硬件配资分析
2.电磁仿真计算绝配~UltraLAB工作站介绍
3.电磁仿真计算硬件配置(单机与集群)推荐
一.电磁仿真计算特点与硬件配置分析
电磁场仿真软件广泛应用于无线和有线通信、计算机、卫星、雷达、半导体和微波集成电路、航空航天等领域,从毫米波电路、射频电路封装设计验证,到混合集成电路、PCB板、无源板级器件、RFIC/MMIC设计,天线设计,微波腔体、衰减器、微波转接头、波导录波器等设计等
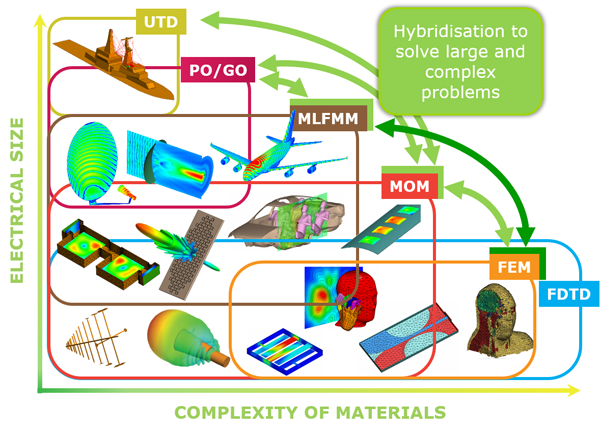
1.1 电磁仿真算法分类、计算特点
计算电磁学(CEM)方法大致可分为2类:精确算法和高频近似方法。
(1)全波精确计算法
包括差分法(FDTD,FDFD)、有限元(FEM)、矩量法(MoM)以及基于矩量法的快速算法(如快速多极子FMM和多层快速多极子MLFMA)等,其中,在解决电大目标电磁问题中最有效的方法为多层快速多极子方法。
(2)高频近似方法
一般可归作2类:一类基于射线光学,包括几何光学(GO)、几何绕射理论(GTD)以及在GTD 基础上发展起来的一致性绕射理论(UTD)等;另一类基于波前光学,包括物理光学(PO)、物理绕射理论(PTD)、等效电磁流方法(MEC)以及增量长度绕射系数法(ILDC)等
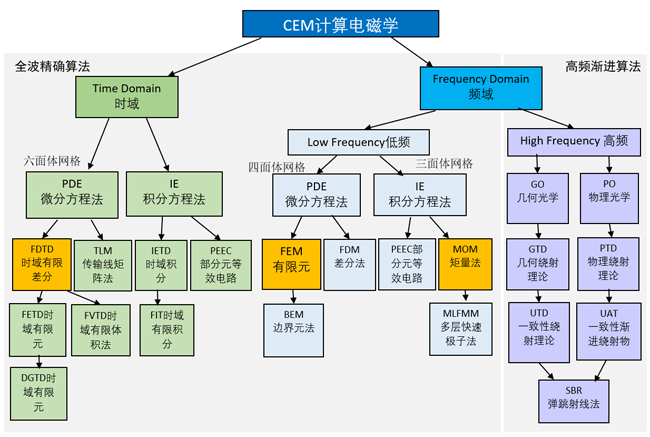
算法计算特点汇总如下
|
NO |
关键项 |
时域算法 |
频域算法 |
||
|
1 |
主要算法 |
时域有限差分 FDTD |
时域有限积分 FIT |
有限元 FEM |
矩量法 MOM |
|
2 |
典型软件 |
EMPIRE XPU XFDTD EMPro |
CST |
HFSS EMPro JMAG FLU |
FEKO Momentum Sonnet |
|
3 |
计算特点 |
线性加速比高、高度多线程, 支持多核CPU 支持大型GPU 内存要求不高 回写很少 |
多线程,线性加速有限 支持多核CPU并行求解 内存要求高 回写有
|
||
小结
1.时域算法,属于显式算法,传统的CPU多核加速比好,核数越多计算越快,此外,并行度高,支持GPU加速计算,注意大部分求解器对GPU要求是双精度计算为主,也就是说需要用双精度性能高的GPU卡
2 频域算法,属于隐式算法,支持多核并行计算,但核数并行计算有限,不支持GPU计算,提升性能的手段,就是提升CPU的频率,足够大的内存,值得注意当内存非常大的时候(超过192GB),硬盘io性能非常关键
1.2 对并行计算求解过程分析
如何配置CPU要根据求解过程和算法特点,尤其要了解时域、频域两大算法特点紧密结合,这样才能更高效更合理,从并行求解流程图看,循环计算过程是单核和多核交叉过程
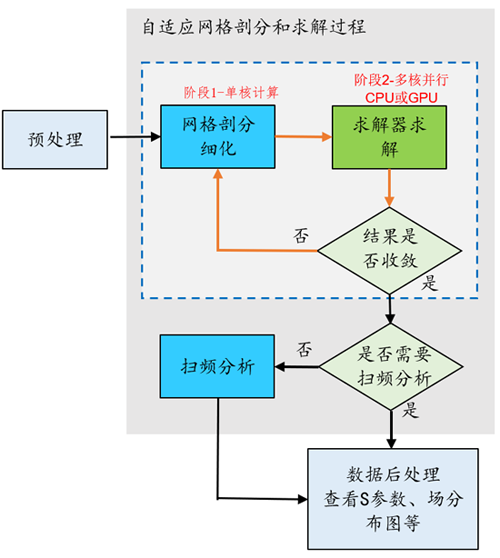
上图可以看出,CPU选型非常重要,CPU睿频足够高,大幅缩短【阶段1】求解时间,和整机足够核数+高频运行,大幅缩短【阶段2】的求解器解算时间
常规工作站卖家,提供的机器往往多核忽视了睿频的重要性,整个计算过程效率非常低,
因此 硬件配置注意:
1.如果是时域算法为主,例如 FDTD、FIT求解器,由于并行度高,工作站配置尽量多核,可显著提升求解速度,同时注意阶段1睿频高的处理器更快,如果是以GPU计算为主,可以配置CPU频率高,核数少的,这样整个过程显著提升
2.如果是隐式算法为主,例如 FEM,MOM求解器,由于并行度有限,一定要睿频尽可能高,同时保证足够的核数的并行,这样整个求解过程无死角瓶颈
3.如果是多种算法并用,CPU要足够核数与高睿频之间选择一个兼顾的规格,三种应用(时域算法、频域算法、混合算法)都均能确保工作站硬件计算性能最大化
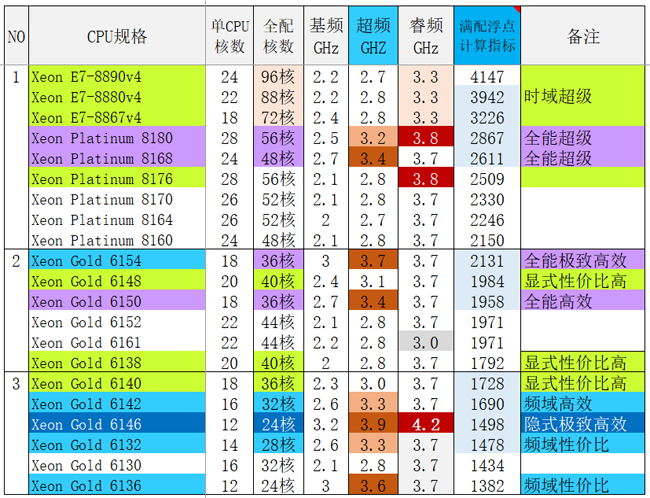
考虑到上述计算特点,CPU的选择对整个求解过程极其重要,下面是最新上市的intel Xeon Schalable(可扩展)处理器多种规格,UltraLAB选型分析:
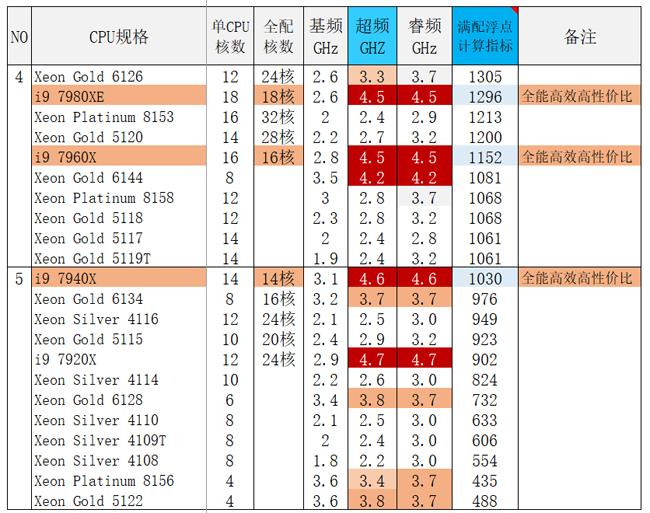
1.3 CEM求解规模与硬件配置推荐
a)基于时域算法~UltraLAB硬件配置参考(CPU类)
|
NO |
分类 |
规模划分 |
核数 |
全核频率 |
睿频 |
内存 |
并行存储 |
|
1 |
小规模 |
<50倍波长 |
14核 |
4.6GHz |
4.6GHz |
32GB |
|
|
18核 |
4.5GHz |
4.5GHz |
64GB |
|
|||
|
2 |
中等规模 |
50~100倍波长 |
36核 |
3.1GHz |
3.7GHz |
64GB |
|
|
40核 |
3.1GHz |
3.7GHz |
96GB |
|
|||
|
3 |
大规模 |
100~200倍波长 |
48核 |
3.5GHz |
3.7GHz |
96GB |
|
|
56核 |
3.3GHz |
3.8GHz |
192GB |
13*4TB |
|||
|
4 |
超大规模 |
>200倍波长 |
96核 |
2.8GHz |
3.3GHz |
512GB |
13*4TB |
b)基于频域算法~UltraLAB硬件配置参考
NO 分类 规模划分 核数 全核频率 睿频 内存 并行存储 1 小规模 <20万网格(</100万未知量) 14核 4.6GHz 4.6GHz 128GB 20万~80万网格(100~400万未知量) 18核 4.5GHz 4.5GHz 192GB 2 中等规模 80万~200万网格(400万~1000万未知量) 24核 4GHz 4.2GHz 256GB 200万~500万网格 36核 3.7GHz 3.7GHz 384GB 8*4TB (1000万~2500万未知量) 3 大规模 500万~1000万网格(2500万~5000万未知量) 48核 3.5GHz 3.7GHz 768GB 10*4TB 4 超大规模 1000万~2000万网格 (5000万~1亿未知量) 56核 3.3GHz 3.8GHz 1.5TB 13*4TB 5 超大规模 >2000万网格(>1亿个未知量) 集群18*6 =108 4.4GHz 4.4GHz 192GB 并行存储
c)基于超大规模时域算法求解GPU选型
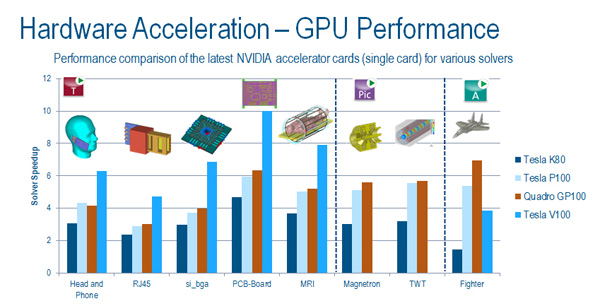
如果以GPU求解为为主,可选的GPU卡参考下表
No 型号 显存(MB) CUDA核 显存带宽 (GBs) 浮点计算指标 TFlops -单精度 浮点计算指标 TFlops -双精度 散热 1 Tesla V100 16GB HBM2 5120 900 14.90 7.45 服务器 2 Tesla P100 16GB HBM2 3584 721 9.52 4.76 服务器 3 Tesla P100 12GB HBM2 3584 721 9.52 4.73 服务器 4 Quadro GV100 32GB 5120 870 14.85 7.42 主动式 5 Quadro GP100 16GB HBM2 3584 717 10.25 5.13 主动式 6 Quadro K6000 12GB 2880 288 5.18 1.73 主动式 7 Quadro K5200 8GB 2304 192 3.07 1.03 主动式
#p#page_title#e#
二.基于电磁仿真计算的UltraLAB机型介绍
UltraLAB是西安坤隆计算机科技有限公司推出的定制图形工作站品牌,经过多年发展,该产品拥有傲视群雄的三大领先优势:先进计算硬件架构、完整齐全行业应用定制方案、专业硬件系统优化技术,大幅超越同类的“图形工作站”产品,我们提供基于电磁仿真计算应用最快硬件架构产品系列
2.1 极速图形工作站H490介绍

配置特点:
(1)CPU具有超高的频率,中小规模时域与频域求解,发挥极致性能
6核5.0GHz,8~10核4.8GHz,12~14核4.6GHz,16~18核4.4GHz
(2)GPU 支持双GPU架构超算
显著优势:
和市场上单路cpu架构的工作站(单Xeon E5v4,单Xeon W-2100系列,单Xeon Schalable系列)相比,拥有超高频率,在多核并行计算(特别是频域求解),性能出众
2.2 高性能计算工作站EX620

配置特点:
CPU 支持双Xeon Schalable(可扩展)处理器,拥有更高频率和更低延迟,中大规模时域与频域求解,发挥极致性能
提供规格:
24核*4GHz/4.2GHz
36核3.7GHz/3.7GHz
40核3.1GHz/3.7GHz
48核*3.5GHz/3.7GHz
56核*3.3GHz/3.8GHz
GPU 支持双GPU架构超算
显著优势:
和市场上常规双路cpu工作站(双Xeon E5v4,双Xeon Schalable系列)相比,拥有更高频率,多核并行计算(时域、频域算法),定位精准高效,显式计算(EX620i)、显式隐式计算通吃(EX620)
2.3 超大规模仿真计算机型Alpha720

配置特点:
CPU 支持4颗Xeon E7v4处理器(最高到96核),拥有更高频率和更低延迟,超大规模时域算法求解,极致性能
提供规格:72核2.8GHz,96核2.7GHz
GPU 支持双GPU架构超算
显著优势 市面上唯一的最快时域求解(CPU计算架构)工作站,极致性能还静音
2.4 图灵超算工作站GX490M或GX620M

GX490M配置特点:
CPU 具有超高的频率,中小规模时域与频域求解,发挥极致性能
提供规格:10核4.8GHz,12~14核4.6GHz,16~18核4.4GHz
GPU 支持7块双槽GPU卡
GX620M配置特点:
CPU 支持双Xeon Schalable(可扩展)处理器,拥有更高频率和更低延迟,中大规模时域与频域求解,发挥极致性能
提供规格:24核4GHz,36核3.7GHz,40核3.1GHz,48核3.5GHz,56核3.3GHz
GPU 支持9块双槽GPU卡
显著优势 市面上唯一的基于办公环境(静音级)最强大GPU超算性能时域求解计算系统,同时兼顾频域隐式算法极致性能展现
各种机型性能与差异对比表
NO 机型 硬件配置特点 适合应用 1 H490 单CPU+双GPU (14核4.7GHz,18核4.5GHz) 中小规模频域、时域算法求解 2 EX620i 双CPU(56核)+双CPU 大规模时域、频域算法求解 3 EX620 双CPU(56核)+双GPU+并行存储 大规模的全能求解 4 GX490M 单CPU+7个GPU+并行存储 超大规模时域GPU超级 5 GX620M 双CPU(56核)+9个GPU+并行存储(16) 超大规模全能求解、时域GPU求解 6 Alpha720 四CPU(96核)+双GPU+并行存储 超大规模CPU架构时域求解 No 产品系列 主要配置 价格 备注 1 UltraLAB H490 14632-S5TBA intel第7代至尊处理器(14核4.6GHz+睿频4.6GHz) /32GB DDR4 2666/512GB SSD +2TBSATA企业级/QP600 2GB/23"图显 39,990 CPU全能高效、高性价比 2 UltraLAB H490 14464-S5TCA intel第7代至尊处理器(18核4.4GHz+睿频4.5GHz)/64GB DDR4 2666/500GB SSD+4TB SATA企业级/Quadro K6000 12GB/23"图显 72,000 CPU+GPU全能极致高性价比 3 UltraLAB EX620i 24096-SATCB 2*Xeon Gold6146处理器(24核4.0GHz,睿频4.2GHz) /96GB DDR4 2666/1TB SSD+6TB SATA /QP2000 5GB/23"图显 112,000 频域极致性能 4 UltraLAB EX620i 23196-SATCE 2*Xeon Gold6148处理器(40核3.1GHz+睿频3.7GHz) /96GB DDR4 2666/1TB SSD +6TB SATA /Quadro K6000 12GB/23"图显 126,000 CPU+GPU时域全能求解 5 UltraLAB EX620 237192-SA28TB 2*Xeon Gold6154处理器(36核3.7GHz+睿频3.7GHz) /192GB DDR4 2666/1TB SSD+28TB并行存储/QP2000 5GB/23"图显 145,000 CPU全能高效 6 UltraLAB EX620 23596-MSATCC 2*Xeon Platinum8168处理器(48核3.5GHz +睿频3.7GHz) /96GB DDR4 2666 /1TB闪电二代+1TB SSD+6TB SATA/QP4000 8GB /23"图显 189,000 时域求解 7 UltraLAB EX620 23596-MSATCC 2*Xeon Platinum8168处理器(48核3.5GHz +睿频3.7GHz) /192GB DDR4 2666 /2TB SSD +28TB并行存储/QP4000 8GB /23"图显 215,000 CPU全能高效 8 UltraLAB EX620 233384-SB28TC 2*Xeon Platinum 8180(56核3.3GHz+睿频3.8GHz) /384GB DDR4/2TB SSD +28TB并行存储/QP4000/23"图显 285,000 CPU全能高效 9 UltraLAB Alpha720 427256-SB42TF 4*Xeon E7 8890v4(96核2.7GHz+睿频3.3GHz)/256GB DDR4/2TB SSD +42TB并行存储/Quadro GP100/32"-2K图显 399,990 超大规模CPU+GPU时域求解
#p#page_title#e#
三.电磁仿真计算硬件配置(单机与集群)推荐
提供单机CPU、单机GPU、集群架构的全面完整,代表追求目前最快计算架构硬件配置方案
3.1 基于多种算法(CPU计算)单机工作站硬件配置方案
3.2 基于时域求解(GPU计算架构)单机硬件配置方案 No 产品系列 主要配置 价格 GPU指标 1 UltraLAB GX490M 14832-S5TB2E intel第7代至尊处理器 (10核4.8GHz+睿频4.8GHz) /32GB DDR4 2666/500GB SSD +4TB SATA企业级 /2*Quadro K6000 12GB/23"图显 87,500 3.46Tflops 2 UltraLAB GX490M 14464-S5TC4E intel第7代至尊处理器 (18核4.5GHz+睿频4.5GHz) /64GB DDR4 2666/500GB SSD+4TB SATA企业级/4*Quadro K6000 12GB/23"图显 159,990 6.92Tflops 3 UltraLAB GX620M 23196-SATD2F 2*Xeon Gold6148处理器 (40核3.1GHz,睿频3.7GHz) / 96GB DDR4 2666/1TB SSD+6TB SATA / 2*Quadro GP100 16GB HBM2/23"图显 228,000 10.2Tflops 4 UltraLAB GX620M 234192-SB28T8E 2*Xeon Platium8168处理器 (48核3.4GHz+睿频3.7GHz) / 192GB DDR4 2666/ 2TB SSD +28T并行存储 /8*Quadro K6000 12GB/23"图显 365,000 13.8Tflops 5 UltraLAB Alpha720 427256-SB42T2F 4*Xeon E7 8890v4 (96核2.7GHz+睿频3.3GHz )/ 256GB DDR4/2TB SSD +42TB并行存储/ 2*Quadro GP100/32"-2K图显 399,990 10.2Tflops 6 UltraLAB GX620M 233192-SB28T4F 2*Xeon Platinum 8180 (56核3.3GHz+睿频3.8GHz) / 192GB DDR4/2TB SSD +28TB并行存储/ 4*Quadro GP100/32"-2K图显 499,990 20.4Tflops 7 UltraLAB GX620M 233384-SB36T8F 2*Xeon Platinum 8180 (56核3.3GHz+睿频3.8GHz) / 384GB DDR4/2TB SSD +36TB并行存储/ 8*Quadro GP100/32-2K"图显 758,000 40.4Tflops
3.3 基于分布式集群的硬件配置方案 NO 货物名称 型号 数量 单价 小计 1 主计算节点 18核4.4Ghz/128GB DDR4 2666 /NVS310/500GB SSD工作站级/4U机架式/无显示器 1 55000 55000 2 从计算节点 18核4.4Ghz/64GB DDR4 2666 /NVS310/500GB SSD工作站级/4U机架式/无显示器 5 46500 232500 3 管理/ 存储节点 4核4Ghz/32GB DDR4 ECC/集成显卡/256GB SSD+28TB单通道并行存储/4U机架式/23"图显 1 36500 36500 4 网络设备 16口万兆交换机 1 9500 9500 5 机柜 42U服务器机柜(含PDU机柜插座) 1 3500 3500 6 KVM 8口 HDMI KVM切换器 1 2800 2800 7 高速交换机 Mellanox 12口56Gbps交换机 1 39500 39500 8 IB卡 Mellanox IB卡56Gbps,含2米线 7 4500 31500 9 10 11 12 13 累计(人民币) 410800 安装调试费用(累计金额*10%) 41080 合计: ¥451,880
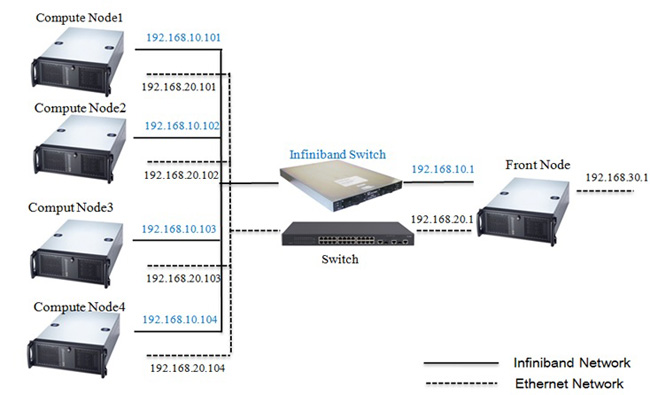
方案1 基于CPU计算的分布式集群方案
方案2 基于CPU+GPU异构超算的分布式集群方案
NO 货物名称 型号 数量 单价 小计 1 主计算节点 18核4.4Ghz/128GB DDR4 2666 /Quadro K6000/ 500GB SSD工作站级/4U机架式/无显示器 1 75500 75500 2 从计算节点 18核4.4Ghz/64GB DDR4 2666 /Quadro K6000/ 500GB SSD工作站级/4U机架式/无显示器 5 67000 335000 3 管理/存储节点 4核4Ghz/32GB DDR4 ECC/集成显卡/256GB SSD+28TB单通道并行存储/4U机架式/23"图显 1 36500 36500 4 网络设备 16口万兆交换机 1 9500 9500 5 机柜 42U服务器机柜(含PDU机柜插座) 1 3500 3500 6 KVM 8口 HDMI KVM切换器 1 2800 2800 7 高速交换机 Mellanox 12口56Gbps交换机 1 39500 39500 8 IB卡 Mellanox IB卡56Gbps,含2米线 7 4500 31500 9 10 11 12 13 累计(人民币) 533800 安装调试费用(累计金额*10%) 53380 合计: ¥587,180
说明:
(1)上述报价仅仅是硬件系统,还需要作业调度系统及安装调试、培训、维护费用
(2)该集群中,每个计算节点比市场上低频双Xeon架构配置,性能更高,保证循环过程中,每个环节计算性能发挥到极致
方案咨询
UltraLAB图形工作站供货商:
西安坤隆计算机科技有限公司
国内知名高端定制图形工作站厂家
业务电话:400-705-6800
咨询微信号:



