






极致性能巅峰:100GB/s(800Gbps)超高带宽全闪存存储服务器
海量、高并发、不卡之王---N600C超级混合闪存存储服务器介绍
https://www.xasun.com/article/150/2819.html
—— 面向AI、HPC与核心业务的极致性能存储引擎
在数据爆炸式增长的AI大模型训练、高性能计算(HPC)、实时数据分析和高并发核心业务场景中,存储性能已成为系统整体效率的决定性瓶颈。为此,我们推出新一代100GB/s 超高带宽全闪存存储服务器,以 PCIe 5.0 架构为核心,打造真正面向未来的数据基础设施。
架构级性能突破,释放全闪潜力
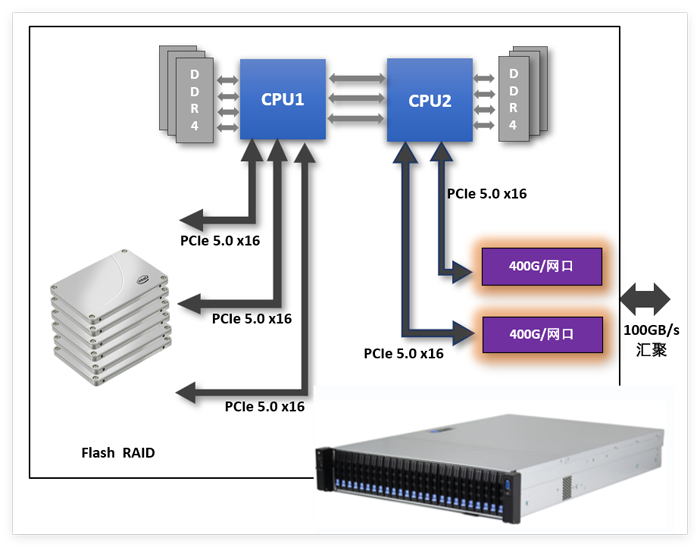
该产品采用 双路高性能处理器架构,支持:
- 2 × Intel® Xeon5代可扩展处理器
- 256GB 大容量缓存内存
- 全 PCIe 5.0 高速互连设计
通过CPU直连PCIe 5.0 x16 通道,将计算、存储与网络进行深度整合,避免传统存储架构中的瓶颈与拥塞,实现真正线速、低延迟的数据访问能力。
纯 NVMe 全闪设计,极致吞吐与低延迟
- 支持4~20块 U.2 NVMe全闪存盘
- 全盘直连PCIe 5.0通道
- 内置高性能Flash RAID 架构
在高并发随机读写及大规模顺序访问场景下,系统可实现:
- 最高 100GB/s 聚合带宽
- 微秒级访问延迟
- 持续稳定的 IOPS 输出
相比传统 SAS/SATA 或混合存储方案,性能提升可达数倍至一个数量级。
400G/800G超高速网络,数据直达算力核心
系统原生支持:
- 400Gbps/800Gbps 超高速网络接口
- 多端口并行设计,支持带宽聚合
- 面向 RDMA、NVMe-oF、分布式存储与 AI 集群优化
在 AI 训练、分布式计算和多节点并行访问场景中,可将数据以最短路径、最低延迟直接输送至 GPU/CPU 计算节点,显著提升整体算力利用率。
面向未来的应用场景
AI 与大模型训练
- 数据加载速度大幅提升
- 减少 GPU 等待时间
- 适用于 LLM、CV、自动驾驶、生命科学 AI
高性能计算(HPC)
- CFD、CAE、量子化学、天体物理
- 海量并行 I/O 与高速检查点写入
科研与生命科学
- 基因测序、蛋白质模拟
- 药物分子设计与仿真:为 Gaussian 16 或 Schrödinger 等软件提供极速暂存盘 (Scratch) 支撑,缩短复杂机理模拟周期
- 大规模实验数据实时存储与分析
金融高频交易与实时分析
- 高频交易 在亚毫秒级延迟内处理超大规模市场数据流,提升决策时效性。
- 实时风控与日志分析
- 超低延迟、超高并发访问
数据中心与私有云
- NVMe over Fabrics
- 高性能存储池
- 软件定义存储(SDS)底座
六大典型应用的性能提升汇总
应用场景
典型特点
性能瓶颈
整体性能提升
关键改善点
备注
1
仿真计算集群(CAE/ CFD/FEM)
大量中间结果写入
checkpoint / restart 频繁
多节点并行 I/O 明显
并行文件系统带宽
元数据与小文件 I/O
I/O 密集型仿真:提升 2~5 倍
强计算型仿真:提升 20%~50%
Checkpoint 时间 ↓ 60%~80%
多节点同时写盘不再“排队”
仿真任务失败重启时间显著缩短
客户感知最强的场景之一
2
人工智能训练计算(AI
Training)
大规模数据集反复读取
多卡/多节点并行训练
数据加载常成为 GPU 等待点
数据加载速度
GPU 空转率
单机多卡训练:提升 30%~80%
多节点分布式训练:提升 1.5~3 倍
数据准备阶段:提升 3~10 倍
GPU 利用率从 60% → 90%+
Epoch 时间明显缩短
小样本频繁迭代效率大幅提高
对“GPU 很贵”的客户,价值非常直观
3
金融高频交易/风险计算/回测
低延迟、确定性 I/O
大量历史数据快速扫描
并发读写极高
存储延迟抖动
数据回放速度
批量回测 / 风险计算:提升 3~6 倍
实时行情分析:延迟降低 50%~80%
数据加载时间:缩短 70%~90%
延迟更稳定(P99 改善明显)
更适合 FPGA /
GPU 协同计算
回测周期从“小时级”到“分钟级”
金融客户更关注“稳定 + 可预测”
4
生物信息分析(基因组 / 蛋白组)
海量小文件(FASTQ
/ BAM / VCF)
多线程并行读写
I/O 明显成为瓶颈
小文件随机 I/O
并行样本处理时的磁盘争用
全流程分析:提升 2~4 倍
比对 / 拼接阶段:提升 3~6 倍
多样本并行:吞吐提升 5 倍以上
样本处理批量能力显著增强
分析队列等待时间大幅下降
更适合自动化流水线(Pipeline)
这是全闪存优势最典型的行业之一
5
海量图像处理 / 视觉计算 / 遥感
大文件顺序读写 + 高并发
GPU/CPU 并行处理
数据流持续不断
存储吞吐
数据预处理阶段
批量图像处理:提升 3~8 倍
实时/准实时处理:提升 2~4 倍
数据预处理阶段:提升 5~10 倍
图像加载不再拖慢 GPU
更适合视频流 / 遥感批处理
支撑更高分辨率与更大数据规模
6
半导体芯片设计与仿真(EDA)
(1)极端 I/O 密集型应用
数百万~上亿级小文件(log、netlist、db、waveform)
大量随机读写(4K~64K)
频繁创建、删除、扫描目录
(2)高并发、多用户、多任务
同一时间运行:
多个仿真任务
大规模 Regression
多名工程师共享集群
数百~上千 CPU 核心并发访问存储
(3)强依赖低延迟与稳定性
对平均延迟不敏感
对P99/P999延迟极其敏感
延迟抖动会直接拉长仿真时间
(4)工作负载阶段性波动明显
白天:多用户交互式任务
夜间:大规模回归仿真
存储系统需要持续高性能输出
小文件 IOPS 不足 仿真启动慢、回归任务排队
存储延迟抖动 同一任务多次运行时间差异大
Metadata 性能差 目录扫描、文件创建极慢
网络带宽不足 多节点并发时吞吐急剧下降
多用户争用 用户一多性能“断崖式”下滑
(1)单任务性能提升
RTL/门级仿真:提升1.5~3倍
综合/布局布线:提升30%~80%
时序分析/
Signoff:提升 1.5~2.5 倍
(2)多任务并行 / 回归测试
Regression吞吐:
提升3~6 倍
并发任务数量:提升 2~4 倍
峰值负载下性能稳定输出
(3)整体设计周期
缩短 30%~50%
Tape-out 阶段效率显著提高
1. 小文件与 Metadata 性能飞跃
NVMe 并行访问
大内存缓存(256GB)
文件创建/删除/扫描速度提升数倍
直接效果
仿真启动更快
回归任务不再排队等 I/O
2.低延迟、低抖动(EDA最在意)
亚毫秒级稳定访问
P99延迟显著下降
直接效果
同一仿真多次运行时间更稳定
夜间批量任务完成时间可预测
3.并发能力大幅提升
100GB/s级存储带宽
400/800Gbps网络
多节点并行访问不争抢
直接效果
支撑更多工程师同时工作
集群规模线性扩展
4. 回归仿真与 Signoff 阶段优势明显
高并发小文件读写
大量中间结果生成
直接效果
回归测试时间从“天级”降至“小时级”
缩短芯片设计关键路径
No
产品核心优势一览
- 100GB/s 超高聚合带宽
- 双路Xeon5代处理器(面向最大120个并发I/O请求)
- 256GB高速缓存
- 4~20块U.2 NVMe全闪盘(容量从50TB~540TB)
- PCIe 5.0 全链路直连
- 400G/800G高速网络接口
- 面向AI与未来算力的可扩展架构
全闪存存储服务器硬件配置推荐(机型:UltraLAB N660CF)
|
No |
关键指标 |
方案1 |
方案2 |
方案3 |
||
|
A1标准配置 |
||||||
|
1-1 |
平台 |
2U机架式 硬盘位:24盘位2.5寸热插拔 PCI扩展槽:4*PCIe 5.0 x16,2*PCIe 5.0 x8 电源:1200W冗余,220V交流 |
||||
|
1-2 |
阵列容量 |
45TB |
100TB |
150TB |
||
|
闪盘数量 |
4个15.36TB |
8块15.36TB |
11块15.36TB |
|||
|
IOPS |
随机读取(100%跨度) 275万 IOPS(4K Blocks) 随机写入(100%跨度) 38万 IOPS(4K Blocks) 延迟随机读取70微秒 延迟随机写入110微秒 延迟顺序读取70微秒 延迟顺序写入7微秒 |
|||||
|
1-3 |
CPU |
2颗Xeon银牌4416+处理器 (40核2.0GHz) |
2颗Xeon银牌4416+处理器 (40核2.0GHz) |
2颗Xeon金牌6530处理器 (64核2.1GHz) |
||
|
1-4 |
芯片组 |
Intel C741 Chips |
||||
|
1-5 |
大缓存 |
192GB DDR5 |
192GB DDR5 |
256GB DDR5 |
||
|
1-6 |
网口 |
2*400G QSFP112,2*千兆光口 |
||||
|
A2性能指标 |
||||||
|
2-1 |
网口端口 |
双口400GB/s,通过汇聚,理论达800GB/s |
||||
|
2-2 |
阵列端口 |
读带宽42GB/s 写带宽30GB/s |
读带宽98GB/s 写带宽70GB/s |
读带宽100GB/s 写带宽100GB/s |
||
|
2-3 |
最大并发IO |
40个 |
40个 |
64个 |
||
|
A3存储管理 |
||||||
|
3-1 |
RAID IOPU |
SupremeRAID IOPU |
||||
|
3-2 |
RAID缓存 |
192GB |
192GB |
256GB |
||
|
3-3 |
RAID级别 |
缺省:RAID5, 可选:RAID 0、1、6、10、50 |
||||
|
3-4 |
管理方式 |
存储RAID管理,监视工具,系统日志,报错处理 |
||||
|
3-5 |
用户管理 |
空间划分、分配 |
||||
|
3-6 |
IPMI功能 |
支持 |
||||
|
A4 扩展能力 |
||||||
|
|
阵列容量 |
最大到600TB |
||||
|
|
CPU |
支持2颗,Xeon4/5代可扩展处理器,最大到128核 |
||||
|
|
内存容量 |
最大到1TB DDR5 4800 RDIMM |
||||
|
|
网口数量 |
最大到2个400GbE或Infiniband接口 |
||||
|
A5 |
操作系统 |
支持Windows Server,Linux |
||||
|
|
报价 |
¥210,000元 |
¥310,000元 |
¥399,990元 |
||
为极致性能而生
这不仅是一台存储服务器,更是一台 数据吞吐引擎。
它专为那些对性能没有妥协空间的应用而设计,帮助用户在 AI、科研与核心业务竞争中抢占先机。
让数据不再成为算力的瓶颈,让存储真正匹配未来计算需求。
想让您的科研与计算业务彻底摆脱 I/O 枷锁吗?
立即联系我们,获取定制化 100GB/s 存储解决方案与实测基准报告。
我们专注于行业计算应用,并拥有10年以上丰富经验,
通过分析软件计算特点,给出专业匹配的工作站硬件配置方案,
系统优化+低延迟响应+加速技术(超频技术、虚拟并行计算、超频集群技术、闪存阵列等),
多用户云计算(内网穿透)
保证最短时间完成计算,机器使用率最大化,事半功倍。
上述所有配置,代表最新硬件架构,同时保证是最完美,最快,如有不符,可直接退货
欲咨询机器处理速度如何、技术咨询、索取详细技术方案,提供远程测试,请联系
UltraLAB图形工作站供货商:
西安坤隆计算机科技有限公司
国内知名高端定制图形工作站厂家
业务电话:400-705-6800
咨询微信号:100369800



