






100GB/s全闪存存储服务器终结仿真集群最大的坑—"I/O 等待”
在高性能计算(HPC)领域,有一个被工程师们心照不宣的“痛点”:无论您花费多少预算去升级最强算力处理器Intel Xeon或AMD 霄龙 或 NVIDIA H100,如果底层的存储系统跟不上速度,这些顶级处理器在大部分时间里其实都在“原地踏步”,等待数据的存取。却依然面临一个共同问题:
CPU/GPU在等数据,仿真任务在“堵车”。
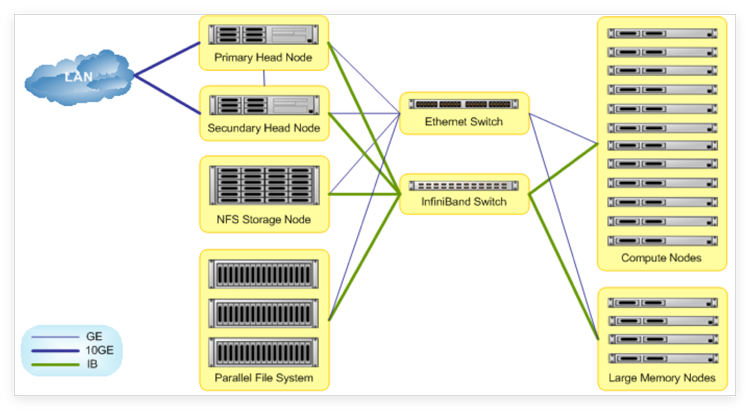
这种现象在电磁仿真、流体动力学(CFD)和结构动力学中尤为显著。今天,我们将探讨100GB/s超高带宽全闪存服务器 如何成为仿真集群的“动力之源”,彻底释放算力潜能。
一、 终结“Scratch”瓶颈:求解器的加速引擎
大多数仿真软件(如HFSS,FEKO、ANSYS Fluent, Abaqus,LS-Dyna、Gaussian 16)在执行复杂矩阵运算时,会产生海量的临时交换文件,即Scratch File。
- 传统痛点:当Scratch文件容量超过物理内存时,系统必须频繁在内存与硬盘间交换数据。即使是普通的NVMe硬盘(约 7GB/s),在应对大规模瞬态仿真时也会显得力不从心,导致CPU占用率忽高忽低。
- 100GB/s 带来的改变:我们的全闪存服务器通过PCIe 5.0 全链路架构,将读写带宽拉升至惊人的 100GB/s。这意味着数据交换几乎是在“瞬时”完成的,CPU 始终保持满载运行。
- 结果:复杂案例的求解时间缩短30%-60%。原本需要跑一个通宵的仿真,现在下午茶时间即可收工。
二、 毫秒级网格剖分:处理千万级精度的底气
仿真第一步,网格必先行。对于拥有数千万甚至上亿个网格的复杂模型(如完整整机电磁环境或精细流体模型),网格剖分与加载过程往往令人抓狂。
- 技术突破:100GB/s 的带宽配合800Gbps 高速网络接口,支持RDMA (RoCE v2) 技术。这意味着大规模模型文件可以跨过内核,直接从闪存映射到计算节点的内存中。
- 效率飞跃:无论是在进行前处理的网格剖分,还是后处理的可视化渲染,100GB/s的带宽确保了即使是GB级单体文件的打开与保存也在“呼吸之间”。
三、 多用户并发:集群性能不“打折”
在典型的科研室或研发中心,仿真集群通常由多个研究员共享。
- 传统存储的噩梦: 当 A 同学在跑 CFD 求解,B 同学在剖分电磁网格,C 同学在读取计算结果时,传统的存储带宽会迅速被瓜分殆尽,导致三个人的进度都陷入停滞。
- 全闪存的韧性: 100GB/s 的总带宽意味着即便有 几十个用户同时进行高强度读写,每个用户分到的带宽依然高达 10GB/s——这仍超过了普通单机电脑的极限。这种“带宽剩余”确保了多任务并行时,互不干扰,集群资源利用率达到 100%。
https://www.xasun.com/article/150/3040.html
四、 投资回报率(ROI):算力即是生产力
对于科研机构和企业研发部门来说,时间就是最昂贵的资产。
- 硬件利用率: 消除 I/O 瓶颈意味着您购买的昂贵 CPU/GPU 不再浪费在等待上。
- 研发周期: 仿真迭代速度提升 1 倍,意味着产品上市或课题结项的时间大幅提前。
- 版权成本优化: 许多仿真软件是按核心数扣费的。通过提升单核的计算产出,您可以在同样的授权规模下完成更多的计算任务。
五、适用场景
- 电磁仿真 / 天线与雷达设计
- CFD 流体仿真 / 气动热分析
- 结构强度 / 疲劳分析
- 多物理场耦合仿真
- 芯片与封装仿真
- 大规模参数扫描与优化计算
算力时代,存储决定上限
如果说10Gbps网口和普通SATA固态是仿真1.0时代,NVMe存储是2.0时代,那么100GB/s带宽全闪存服务器 + 800G 网络互联 则是3.0时代的入场券。
它不只是一台存储设备,它是整个计算集群的“血液循环系统”。只有血流速度足够快,算力大脑才能爆发最强性能。
100GB/s 全闪存服务器不是锦上添花,而是刚需基础设施。
西安坤隆计算机科技有限公司 现已推出定制化100GB/s全闪存仿真计算存储方案。我们不仅提供硬件,更提供针对HFSS、CST、Fluent等主流软件的底层 I/O优化建议。
想要实测 100GB/s 的震撼体验吗? 立即联系我们的技术专家,获取测试报告或预约远程演示。
现在咨询,获取《量化交易存储性能优化白皮书》及实测报告
咨询电话:400-705-6800
咨询微信:100369800
别让IO瓶颈,成为你唯一高速计算等待的风险。


