






微米级精度的算力引擎:工业机器视觉检测系统的硬件配置黄金法则
时间:2026-03-01 01:06:45
来源:UltraLAB图形工作站方案网站
人气:102
作者:管理员
从2D瑕疵检测到3D结构光重建,从毫秒级节拍控制到AI深度学习识别,构建零缺陷制造线的硬件选型之道
在苏州某精密制造工厂的SMT产线上,每秒钟有15块PCB板以0.8m/s的速度通过检测工位。在这不足70毫秒的窗口期内,一套机器视觉系统必须完成:高分辨率成像(5μm/pixel)、焊膏3D体积测量(基于结构光三角测量)、以及基于深度学习的虚焊缺陷识别(推理时间<20ms)。任何一环节的硬件瓶颈——无论是相机接口的带宽不足、GPU的显存延迟,还是CPU的线程调度抖动——都会导致漏检或误检,直接造成下游整机的可靠性危机。
这不是简单的"装个摄像头接电脑"的应用场景,而是现代智能制造中光学、机械、算法与算力深度耦合的系统工程。当工业视觉从传统的模板匹配(Rule-based)演进为AI驱动的像素级语义分割,当检测节拍从秒级压缩到毫秒级,硬件配置的每一个细节都成为决定方案成败的关键。
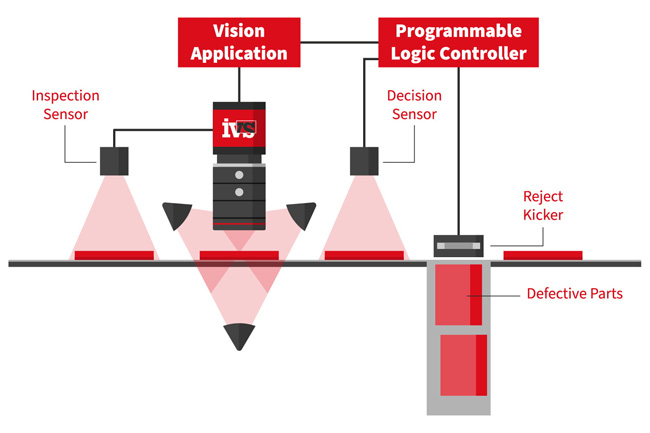
第一章:机器视觉系统的硬件架构全景——不仅仅是"相机+电脑"
一套完整的工业机器视觉检测系统包含四个硬件层次,每个层次都有严格的性能边界:
感知层(Image Acquisition):
-
工业相机:CCD/CMOS传感器(全局快门Global Shutter必备),分辨率从2MP到150MP不等,帧率从30fps到1000fps+(高速场景)
-
光学系统:远心镜头(消除透视畸变)、CCTV镜头(大景深)、液体镜头(快速调焦)、以及结构光/激光投射器(3D成像)
-
照明系统:LED环形光(漫射)、同轴光(镜面反射)、条形光(暗场照明)、频闪控制器(高速冻结运动)
传输层(Data Transport):
-
接口协议:GigE Vision(千兆/万兆网,100m传输)、USB3 Vision(5Gbps,5m限制)、Camera Link(6.8Gbps,需专用采集卡)、CoaXPress(CXP-12单缆12.5Gbps,支持100m,高端科学级)
-
触发同步:硬件触发(Hardware Trigger)通过编码器信号或光电传感器确保相机与运动轴微秒级同步,避免"果冻效应"
计算层(Image Processing):
-
预处理:去噪、白平衡、几何畸变校正(基于FPGA或GPU CUDA)
-
特征提取:传统算法(Blob分析、边缘检测、形态学)或深度学习(CNN推理)
-
决策输出:OK/NG判定、坐标输出给机械臂、数据上传MES系统
执行层(Action):
-
I/O控制:数字IO卡控制剔除机构(气吹/推杆)、PLC通信、光源频闪触发
硬件选型的核心矛盾:在检测精度(高分辨率)、处理速度(低延迟)、系统成本(ROI)之间找到平衡。而这三角关系的支点,在于计算层硬件的精准配置。
第二章:计算平台选型——CPU、GPU、FPGA的三角博弈
工业视觉的计算平台选择,本质上是算法复杂度与实时性要求的权衡:
场景A:传统2D检测(几何测量、OCR、简单瑕疵)
推荐配置:高性能CPU + 大内存带宽
-
CPU:Intel Core i9-14900K(高主频6.0GHz利于单线程图像预处理)或 AMD Ryzen 9 7950X(多核优势处理多相机并行)
-
内存:32GB-64GB DDR5-5600(高频率降低内存延迟,对缓存不友好的图像遍历操作至关重要)
-
存储:512GB NVMe SSD(存储检测日志和NG图像,支持每秒数百张图像的写入)
-
采集卡:GigE接口可直接走主板网卡;Camera Link需插入PCIe采集卡(如Euresys Grablink)
技术要点:此类场景依赖OpenCV优化,需确保CPU支持AVX-512指令集(Intel 13/14代或AMD Zen4),可加速图像滤波和矩阵运算。
场景B:深度学习缺陷识别(AI视觉检测)
推荐配置:GPU加速工作站(CUDA生态)
-
GPU:NVIDIA RTX 4070 Ti SUPER(16GB显存,适合YOLOv8/SegFormer推理)或 RTX A5000(专业卡支持ECC,长时间运行更稳定)
-
显存计算:输入图像尺寸(如4096×3072)× 批次大小(Batch)× 模型参数量(FP32)。对于高分辨率检测,16GB是起步配置。
-
推理延迟:使用TensorRT优化后,RTX 4070 Ti SUPER处理单张5MP图像的语义分割可在15-30ms完成,满足多数产线节拍。
-
-
CPU:AMD Threadripper PRO 5965WX(24核48线程),负责图像采集、预处理和数据流管理,避免GPU被I/O阻塞
-
内存:128GB DDR4-3200 ECC(处理多批次图像缓冲)
关键瓶颈:CPU与GPU间的PCIe带宽。若使用PCIe 3.0 x16(16GB/s),高分辨率图像传输可能成为瓶颈。建议采用PCIe 4.0/5.0平台,或使用零拷贝技术(Zero-Copy,GPU Direct for Video)。
场景C:超高速实时检测(>1000fps或微秒级延迟)
推荐配置:FPGA或视觉专用处理器(VPU)
-
FPGA板卡:如National Instruments FlexRIO或Xilinx Kria SOM,在硬件层面实现并行卷积运算,延迟可控制在微秒级(vs GPU的毫秒级)
-
智能相机(Smart Camera):集成ARM+DSP或NPU(如Intel Movidius Myriad X),适合分布式检测点,减少布线成本
-
采集卡FPGA加速:高级图像采集卡(如Matrox Rapixo)内置FPGA,可在传输至主机前完成预处理(如ROI裁剪、二值化),减轻CPU负担
适用场景:锂电极片缺陷检测(走带速度>100m/min)、高速瓶盖检测(>50,000件/小时)。
第三章:相机接口与采集卡——带宽与距离的精密计算
选择相机接口时,必须精确计算数据通量(Data Throughput):
带宽需求公式:
plain
所需带宽(MB/s) = 分辨率(宽×高) × 位深(Bit Depth)/8 × 帧率(fps) × 通道数(彩色为3,Mono为1) × 开销系数(1.2-1.4)
典型配置对照表:
表格
| 应用场景 | 分辨率/帧率 | 计算带宽 | 推荐接口 | 硬件要点 |
|---|---|---|---|---|
| 电子元器件检测 | 5MP@30fps | ~450MB/s | GigE Vision | Intel i210/i350网卡(支持Jumbo Frame 9KB),开启RSS多队列 |
| PCB AOI | 25MP@10fps | ~750MB/s | USB3 Vision | 独立USB控制器(避免与键鼠共用Root Hub),屏蔽双绞线<3m |
| 锂电池极片 | 12MP@100fps | 3.6GB/s | Camera Link Full (6.8Gbps) | PCIe x4采集卡(如Teledyne Dalsa Xtium),主机需PCIe 3.0 x8以上 |
| 晶圆表面检测 | 71MP@4fps | 1.1GB/s | CoaXPress (CXP-6) | 四通道CXP帧抓取器,支持PoCXP供电,光纤延长<100m |
| 高速运动捕捉 | 1MP@1000fps | 3GB/s | 10GigE (NBASE-T) | 万兆网卡(Intel X550),CAT6A屏蔽网线,交换机支持QoS |
多相机同步的关键硬件:
当系统使用4-8个相机进行360°无死角检测时,必须采用硬件触发同步:
-
编码器输入:采集卡接收伺服电机编码器A/B相脉冲,每N个脉冲触发一次拍摄(等距采样,避免变速影响)
-
光源同步:频闪控制器(Strobe Controller)接收相机触发信号(Trigger Out),在曝光瞬间提供μs级脉冲照明(如1μs@1000A电流),冻结运动模糊
-
PTP/gPTP同步:对于GigE相机,使用精密时间协议(IEEE 1588)确保多相机曝光时间戳误差<1μs
第四章:深度学习视觉检测的硬件深度优化
当缺陷检测从"规则算法"(面积、周长、灰度阈值)转向"AI识别"(划痕、污点、纹理异常),硬件配置需要针对性强化:
1. 训练服务器 vs 推理工作站
-
训练端(离线):需要双卡RTX 4090或A6000(48GB显存可处理更大Batch Size),配备4TB NVMe SSD存储数十万张缺陷样本,用于训练U-Net或Detectron2模型。
-
推理端(在线):单卡RTX 4060 Ti或Jetson AGX Orin(边缘部署)即可,重点在于模型量化(INT8精度)和TensorRT引擎优化。
2. 数据流水线(Pipeline)优化 工业视觉的吞吐量瓶颈常在CPU预处理(图像解码、归一化、Resize)而非GPU推理。解决方案:
-
DALI(NVIDIA Data Loading Library):利用GPU进行图像解码和增强,释放CPU核心用于通信控制
-
多线程缓冲:使用Triple Buffering机制,确保GPU始终有数据可算,避免空闲等待
3. 显存管理策略 高分辨率检测(如50MP工业相机)输入图像本身占300MB显存,若直接送入深度学习模型会导致OOM(Out of Memory)。硬件层面解决方案:
-
Tiled Processing:将大图切分为重叠的小块(如1024×1024)分别推理,再拼接结果。这需要GPU支持动态显存分配和快速上下文切换。
-
模型剪枝与蒸馏:在训练端使用知识蒸馏生成轻量级模型(如MobileNetV3 backbone),降低推理端GPU要求。
4. 边缘计算部署 对于分散的产线(如光伏组件的户外EL检测),采用边缘AI盒子:
-
NVIDIA Jetson AGX Orin:275 TOPS INT8算力,支持多路相机输入,功耗仅60W,无风扇设计(通过被动散热或传导散热适应粉尘环境)
-
Intel NUC 13 Pro + Movidius VPU:适合低功耗场景(<25W),支持OpenVINO加速
第五章:特殊场景的硬件挑战与对策
高精度3D测量(结构光/ToF):
-
投影仪:DLP工业投影(TI DMD芯片),需与相机严格同步(触发信号分路器)
-
计算:相位展开(Phase Unwrapping)和点云配准(ICP算法)计算密集,推荐RTX 4070以上显卡加速
-
内存:处理百万级点云(PLY/PCD格式)需64GB+内存,避免点云处理时的分页
高反光/透明材质检测(玻璃、金属镜面):
-
偏振相机:Sony IMX偏振传感器(四向偏振片),捕捉偏振光信息,需PCIe x4带宽确保4通道数据流不丢帧
-
光源:低角度环形光(Dark Field)+ 偏振滤光片,消除镜面反射
洁净室/防爆环境:
-
无风扇设计:整机被动散热(热管+鳍片),避免粉尘进入(如食品医药包装检测)
-
IP65防护:相机和光源需防尘防水,计算单元置于电气柜内(正压通风)
多光谱/高光谱成像:
-
数据洪流:高光谱相机(如Headwall Photonics)每秒产生2-5GB原始数据(数百个光谱波段),需RAID 0 NVMe阵列(持续写入速度>6GB/s)和100GbE网络实时传输至存储服务器。
第六章:UltraLAB机器视觉计算平台配置方案
方案A:深度学习质检工作站(产线旁部署)
硬件架构:
-
CPU:Intel Core i9-14900K(高主频优化单线程OpenCV操作)
-
GPU:NVIDIA RTX 4070 Ti SUPER 16GB(TensorRT推理核心)
-
内存:64GB DDR5-5600(双通道,低延迟)
-
存储:1TB NVMe Gen4(系统+模型)+ 4TB NVMe(本地NG图像缓存,支持每秒500张JPG写入)
-
采集:1× Camera Link Full帧抓取器(Teledyne Dalsa Xtium-CL)+ 2× Intel I210 GigE网卡(独立通道,避免中断冲突)
-
I/O:National Instruments USB-6501(数字IO卡,连接PLC和剔除机构)
-
机箱:4U工业机箱,前置USB3.0接口(方便维护),支持-20℃~60℃宽温(无风扇散热选项)
软件优化:
-
预装Halcon深度学习插件 + NVIDIA TensorRT 8.6
-
配置MVTec MERLIC或OpenCV 4.8(with CUDA模块编译)
-
实时操作系统(RTLinux或Windows 10 IoT Enterprise LTSC),禁用CPU节能模式(C-State),确保推理延迟抖动<1ms
方案B:多相机高速检测服务器(中央处理架构)
适用场景:锂电池卷绕检测(8相机同步)、汽车零部件全检(12工位)
硬件架构:
-
CPU:AMD Ryzen Threadripper PRO 5975WX(32核64线程),处理多路相机数据并行预处理
-
GPU:2× RTX A5000 24GB(NVLink桥接,处理多批次图像推理)
-
采集卡:2× CoaXPress四通道帧抓取器(Euresys Coaxlink Quad G3),支持8路CXP-12相机(总带宽100Gbps)
-
内存:256GB DDR4-3200 ECC(Registered,支持大容量多路缓冲)
-
网络:双10GigE网卡(Intel X710),连接上游MES系统和下游机械手控制器
-
触发:专用触发分配器(Trigger Distribution Box),接收编码器信号,分路同步至8台相机和光源
架构优势:
-
集中式处理:避免每工位配备独立电脑,降低维护成本
-
数据融合:8路图像在同一内存空间处理,支持跨相机的缺陷关联分析(如追踪同一缺陷在不同角度的成像)
-
热备冗余:双电源+RAID 1系统盘,确保7×24不间断运行
方案C:嵌入式边缘视觉单元(分布式部署)
硬件架构:
-
核心:NVIDIA Jetson AGX Orin 64GB(ARM Cortex-A78AE + Ampere GPU)
-
相机接口:4× GigE(通过PCIe转接卡扩展)或2× USB3.0
-
存储:256GB NVMe SSD(工业级宽温)
-
I/O:8× GPIO(隔离),2× RS-485(Modbus RTU连接PLC)
-
供电:24V DC工业电源,支持POE++(通过网线供电给相机)
-
散热:无风扇导热设计(铝合金外壳),适应粉尘、油污环境(如铸造车间、纺织车间)
适用算法:
-
YOLOv5s/v8n(轻量级目标检测)
-
传统Blob分析(OpenCV优化)
-
支持TensorRT和ONNX Runtime部署
结语:硬件即精度,算力即节拍
在工业4.0的竞赛中,机器视觉已从"辅助检测工具"进化为"质量守门员"和"工艺优化师"。当检测精度要求从毫米级迈向微米级,当处理节拍从秒级压缩到毫秒级,硬件配置的每一个决策——是选择GigE的便捷还是CoaXPress的带宽,是使用CPU的通用性还是GPU的并行性,是采用集中式服务器还是分布式边缘计算——都直接影响着产线的OEE(设备综合效率)和产品的良品率。
UltraLAB机器视觉计算平台,凭借对工业相机接口生态的深度理解、对深度学习推理硬件的精准优化,以及对恶劣工业环境的适应性设计,为电子、锂电、汽车、光伏、医药等行业提供从"图像采集"到"智能决策"的全栈硬件支撑。
让每一帧图像都经过算力的精密审视,让每一个缺陷都无处遁形——这就是智能制造的硬件基石。
【UltraLAB技术团队 | 工业机器视觉与边缘计算硬件专家】
咨询热线:400-7056-800
微信号:xasun001
上一篇:没有了


